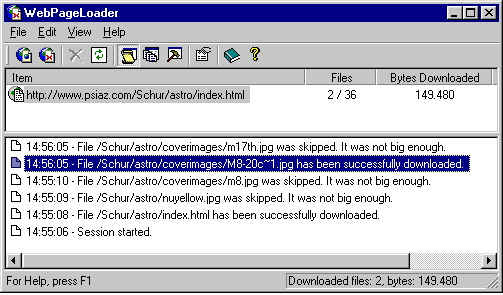
It downloads web pages and entire sequences of files from the internet. A clipboard hook listens for any text copied to the clipboard, which resembles an URL or image filename. So you can open any webbrowser and simply copy the URL to the clipboard to activate it. The application will then present a dialog that allows you to configure an internet download - making it a fully automated, multi-threaded, link-following, file-retrieving web-spider.
It will retrieve all the files you want - and only the files you want - from any part of the Internet. Use filters to select your files based on size or name. Download a complete HTML page or a serie of images.
There are several web-spiders available as shareware, freeware and payware. This spider was created to add an additional feature many of the others are missing: downloading sequences of files without a source link.
The application will preserve the original downloaded pages, so you cannot use it as an offline browser. This is something that may change in the future.
The Source Code
This project is not the most well designed code I have made. The multi-threading support was added relatively late in the implementation process and when the question of thread-safety arrived, it sort of turned into a mess.TODO List
- Make offline browsing possible (turn internet links on the pages into links to the files just downloaded).
- Rework the thread-safe protecting code.
- Add functionality for thread sleep and to skip file download.
Source Code Dependencies
Microsoft Visual C++ 6.0Microsoft MFC Library
Download Files
 | WebPageLoader executable (227 KiB) Source Code (115 KiB) |